
Self-Managing Databricks Groups With Databricks Itself
Databricks itself has admin console for managing groups which is OK (there are silly things like no way to see email addresses of who is in the group). But the main complaint I have is group management - you simply cannot add/remove users without being a global workspace administrator. Hell, you can’t even view group members if you are a normal user.
You could allocate special admins to manage groups but that just introduces a productivity lag. The solution below describes what I came up with and been using for some time. Various methods were tried, but none of them were good enough for me and my users.
Reuse
In order to do some sort of self-management, one needs a user interface. This is an interesting problem to solve, and one could involve some third-party solutions or write their own. Unfortunately there are no good ones - third-party would require installing and managing it (which is almost impossible in tight environments) and writing your own just takes a long time and in addition to that has the previous overhead added on top.
The only easy-to-use and low friction solution was to just use Databricks’ built-in notebook system, it has the following features available out of the box:
- Flexible permission system. You can assign permissions by group, user to view/edit/run etc. This sort of gives you a hint that you can use it to give designated users permissions to do certain operations, if those operations are contained in the notebook.
- Scriptable. You can fetch notebook content using REST API, and you can update notebook programmatically as well.
- Collaborative editing.
Therefore, I’ve created a notebook which essentially list all the users in a group, and allows users to edit it as well.
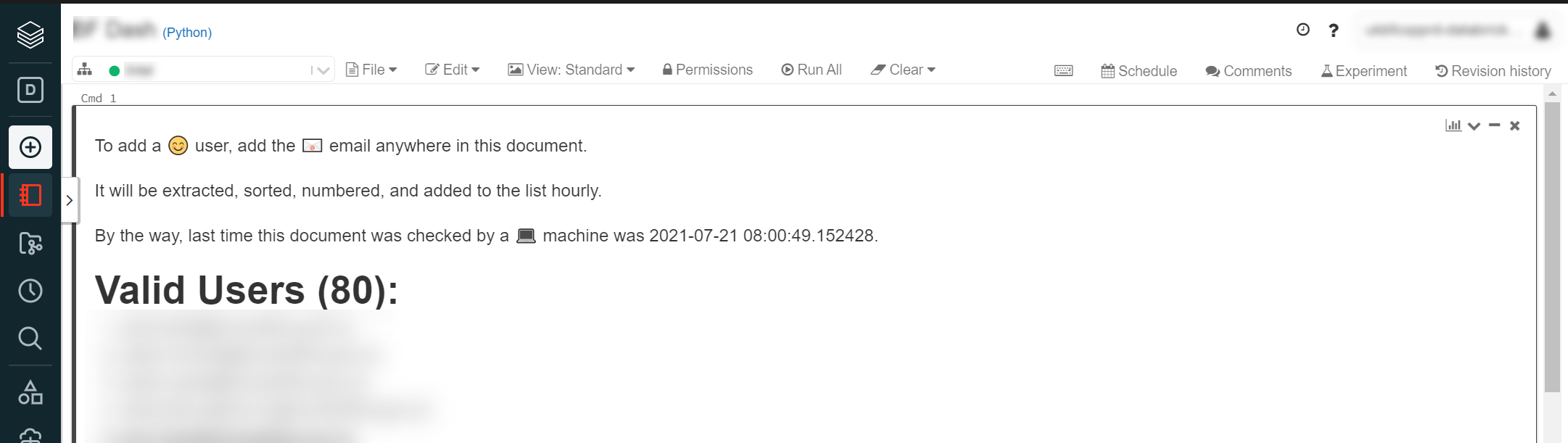
Once an hour a CI/CD task check the notebook, parses out all email addresses, compares them to group membership in the databricks group, and add/removes users in that Databricks group.
Hourly Task
Below is the task workflow that runs periodically:
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-g", help="group name")
parser.add_argument("-n", help="notebook path")
args = parser.parse_args()
group_name = args.g
notebook_path = args.n
users, groups = list_group_members(group_name)
users.sort()
groups.sort()
nb = get_notebook(notebook_path)
cell1 = nb["cells"][0]
src = str(cell1["source"][0])
notebook_emails = extract_email_list(src)
to_add = list(set(notebook_emails) - set(users))
to_remove = list(set(users) - set(notebook_emails))
invalid_users = []
if to_add:
for u in to_add:
print(f"adding {u}")
if not add_group_user(group_name, u):
invalid_users.append(u)
if to_remove:
for u in to_add:
print(f"removing {u}")
add_group_user(group_name, u)
users, groups = list_group_members(group_name)
users.sort()
groups.sort()
md = f"To add a 😊 user, add the 📧 email anywhere in this document.\n\nIt will be extracted, sorted, numbered, and added to the list hourly.\n\nBy the way, last time this document was checked by a 💻 machine was {datetime.now()}.\n\n# Valid Users ({len(users)}):\n\n"
for i, u in enumerate(users):
md += f"{i + 1}. {u}\n"
if invalid_users:
md += f"\n\n# Unrecognised Users ({len(invalid_users)}):\n\n"
for i, u in enumerate(invalid_users):
md += f"{i + 1}. {u}\n"
cell1["source"] = md
set_notebook(notebook_path, nb)
What’s happening here is:
- Group Name and Notebook Path are both passed as command line arguments. Group name is a string, something like “The Group” and notebook path is absolute path in the workspace i.e.
/Management/Groups/My Group. - Listing group members (
list_group_members(group_name)) and sorting them. - Fetch notebook source code (
get_notebook(notebook_path)) in.ipynbformat which is essentially a json document. - Get the first cell of the notebook and extract emails with a regular expression.
- Detect which users need to be added and which removed from the group.
- Perform add and remove.
- Fetch group members again and sort them.
- Generate markdown describing the current membership.
- Update the notebook.
That’s it.
CI/CD Task
I’ve used Azure Pipelines to automate this, and pipeline yaml is presented below:
schedules:
- cron: "0 * * * *"
displayName: Hourly
branches:
include:
- master
always: true
pool:
vmImage: 'ubuntu-latest'
stages:
- stage: Dev
dependsOn: []
variables:
- group: DEV_VARS
jobs:
- job: SelfManagedGroups
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.7.x'
addToPath: true
architecture: 'x64'
- task: CmdLine@2
displayName: 'install python deps'
inputs:
script: 'pip install requests databricks-cli'
- task: CmdLine@2
displayName: 'Group 1'
inputs:
script: 'python ./self_managed_group.py -g "Group 1" -n "/Admin/Databricks/Group 1"'
- task: CmdLine@2
displayName: 'Group 2'
inputs:
script: 'python ./self_managed_group.py -g "Group 2" -n "/Admin/Databricks/Group 2"'
Full Script
import os
import requests
import base64
import json
import re
import argparse
from datetime import datetime
host = os.getenv("DATABRICKS_HOST")
token = os.getenv("DATABRICKS_TOKEN")
base_url = f"{host}api/2.0/"
def list_group_members(group_name: str):
response = requests.get(
f"{base_url}groups/list-members",
headers={"Authorization": f"Bearer {token}"},
json={"group_name": group_name})
response.raise_for_status()
doc = response.json()
users = [x.get("user_name") for x in doc["members"]]
groups = [x.get("group_name") for x in doc["members"]]
return [x for x in users if x], [x for x in groups if x]
def add_group_user(group_name: str, user_name: str) -> bool:
response = requests.post(
f"{base_url}groups/add-member",
headers={"Authorization": f"Bearer {token}"},
json={"parent_name": group_name,
"user_name": user_name})
if response.status_code == 404:
# user does not exist!
return False
response.raise_for_status()
return True
def remove_group_user(group_name: str, user_name: str):
response = requests.post(
f"{base_url}groups/remove-member",
headers={"Authorization": f"Bearer {token}"},
json={"parent_name": group_name,
"user_name": user_name})
response.raise_for_status()
def get_notebook(path: str):
response = requests.get(
f"{base_url}workspace/export",
headers={"Authorization": f"Bearer {token}"},
json={"path": path, "format": "JUPYTER"})
response.raise_for_status()
doc = response.json()
content = doc["content"]
ipynb_string = base64.b64decode(content).decode("utf-8")
return json.loads(ipynb_string)
def set_notebook(path: str, notebook):
content = base64.b64encode(json.dumps(notebook).encode("utf-8")).decode("utf-8")
response = requests.post(
f"{base_url}workspace/import",
headers={"Authorization": f"Bearer {token}"},
json={
"path": path,
"format": "JUPYTER",
"content": content,
"language": "PYTHON",
"overwrite": True})
response.raise_for_status()
def extract_email_list(line: str):
match = re.findall(r"[\w.+-]+@[\w-]+\.[\w.-]+", line)
return match
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-g", help="group name")
parser.add_argument("-n", help="notebook path")
args = parser.parse_args()
group_name = args.g
notebook_path = args.n
users, groups = list_group_members(group_name)
users.sort()
groups.sort()
nb = get_notebook(notebook_path)
cell1 = nb["cells"][0]
src = str(cell1["source"][0])
notebook_emails = extract_email_list(src)
to_add = list(set(notebook_emails) - set(users))
to_remove = list(set(users) - set(notebook_emails))
invalid_users = []
if to_add:
for u in to_add:
print(f"adding {u}")
if not add_group_user(group_name, u):
invalid_users.append(u)
if to_remove:
for u in to_add:
print(f"removing {u}")
add_group_user(group_name, u)
users, groups = list_group_members(group_name)
users.sort()
groups.sort()
md = f"To add a 😊 user, add the 📧 email anywhere in this document.\n\nIt will be extracted, sorted, numbered, and added to the list hourly.\n\nBy the way, last time this document was checked by a 💻 machine was {datetime.now()}.\n\n# Valid Users ({len(users)}):\n\n"
for i, u in enumerate(users):
md += f"{i + 1}. {u}\n"
if invalid_users:
md += f"\n\n# Unrecognised Users ({len(invalid_users)}):\n\n"
for i, u in enumerate(invalid_users):
md += f"{i + 1}. {u}\n"
cell1["source"] = md
set_notebook(notebook_path, nb)
Em, excuse me! Have Android 📱 and use Databricks?
You might be interested in my totally free (and ad-free) Pocket Bricks . You can get it from Google Play too:
![]()
To contact me, send an email anytime or leave a comment below.