
Synchronising two SQL Server instances (one way, or potentially both)
Recently I had a problem to move data from on premise SQL Server to Azure SQL. More than that, customer also wanted to use both databases because there is still a lot of software running on premise. My task was to keep some of the tables in sync one way (from on prem to cloud). Unfortunately existing solutions are either too chunky and hard to deploy or too expensive and don’t do the job correctly, therefore I though I could create my own in a short time (which I did).
When you look at the problem there are a few options:
-
Try to figure out how SQL Profiler captures all queries which was my initial thought. Unfortunately this mechanism doesn’t work with Azure databases.
-
Use existing developer library like Microsoft Sync Framework, which is great by the way, and does the job, but has one real showstopper – can only be installed with an MSI package and depends on local COM components installed into the system. It just doesn’t work in continuous deployment world.
-
Use a wonderful technology called SQL Server Change Tracking built into SQL Server 2008 R2 and higher. Both on premise installations and SQL Azure satisfy this requirement!
SQL Server Change Tracking
Change tracking is like a log file for your tables. As official website says:
Change tracking is a lightweight solution that provides an efficient change tracking mechanism for applications. Typically, to enable applications to query for changes to data in a database and access information that is related to the changes, application developers had to implement custom change tracking mechanisms. Creating these mechanisms usually involved a lot of work and frequently involved using a combination of triggers, timestamp columns, new tables to store tracking information, and custom cleanup processes.
Change tracking is really lightweight and can be enabled per table in the source database. It also doesn’t require lots of storage space and rotates logs based on your configuration. Essentially Change Tracking records a minimum list of actions executed on rows in your database, with it’s own limitations:
- Only change type (insert, update or delete) and row key is recorded.
- Change Tracking does not log every action i.e. let say you have inserted a row, then updated it. If you ask SQL server what has happened it will tell that a row was inserted, that’s it. It kind of makes sense when you only have row ID and operation type.
- Changes to tables schema such as dropping table, constraint, column, adding or renaming tables, adding or dropping indexes, truncating a table is not tracked at all.
Therefore it’s not suitable for any serious auditing, however is perfect for data synchronisation. If you know which operation was performed on which row you can then query database for the latest information and push the data to the second server.
Enabling Change Tracking
Change Tracking can be enabled in one of two ways
SQL Server Management Studio
Right-click database properties, go to Change Tracking and set the appropriate parameters. They are self explanatory and context help is great.
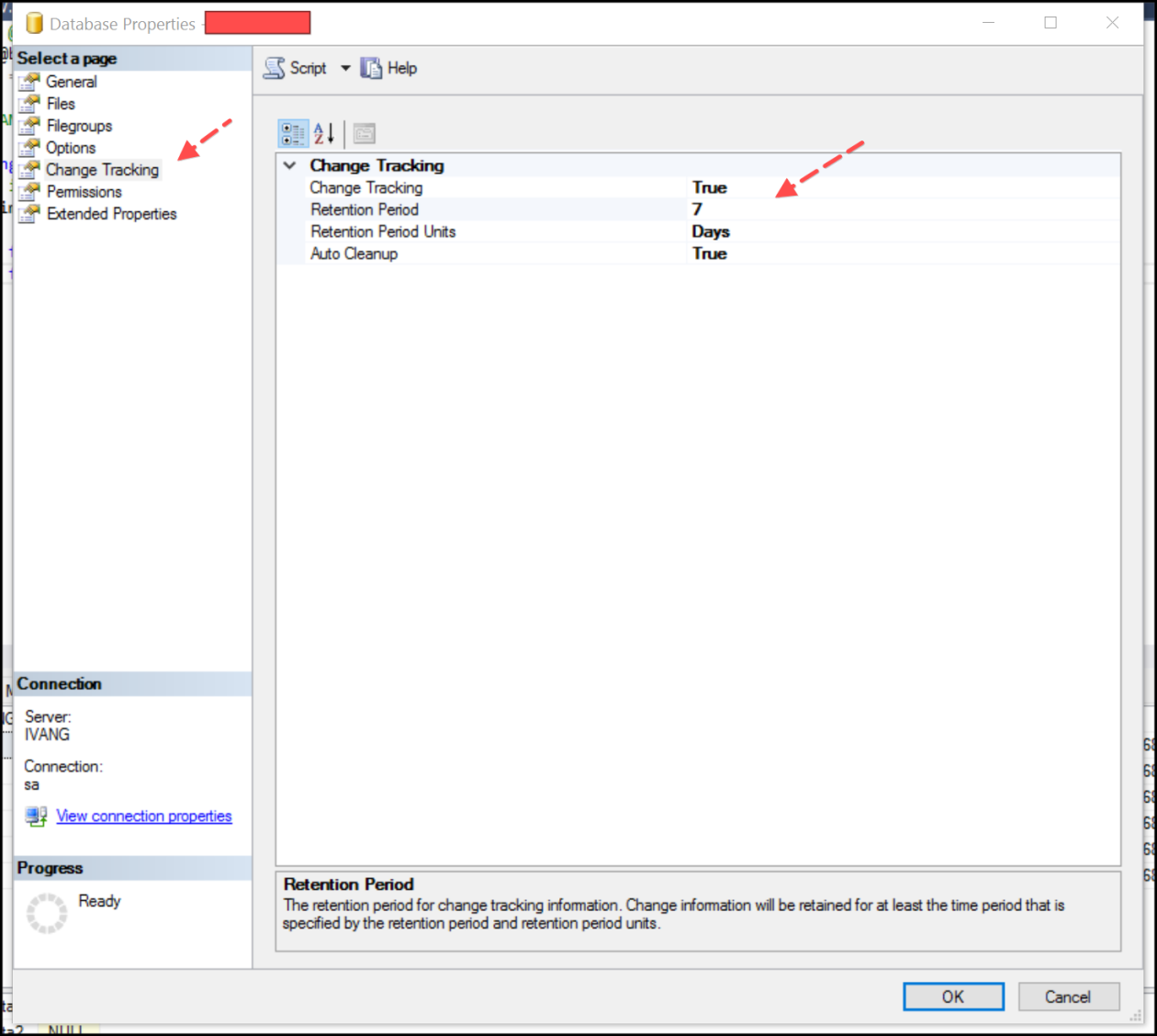
Doing this enables change tracking on database level, however changes to any tables are not tracked. You have to now enabled tracking for tables you want. As usual right-click the table, go to Change Tracking and set the option to True (this is the only one you can set).
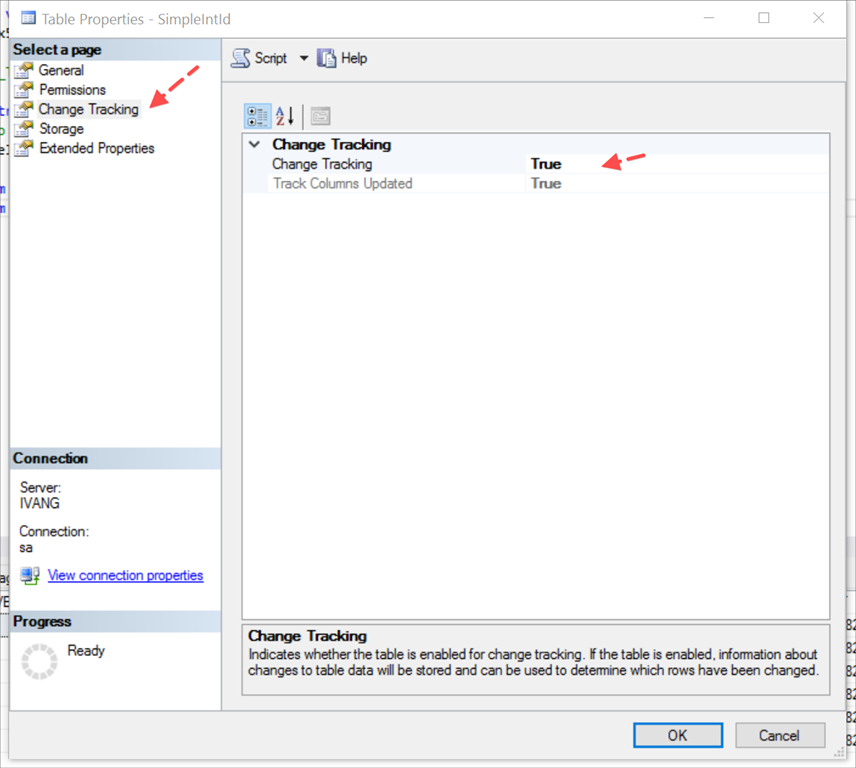
SQL Scripting
Enable database change tracking:
alter database DatabaseName set change_tracking=ON (change_retention = 7 days, auto_cleanup=on)
Check if database tracking is enabled:
select count(*) from sys.change_tracking_databases where database_id=DB_ID('DatabaseName')
Enable table change tracking:
alter table TableName enable change_tracking with (track_columns_updated=on)
Check if table change tracking is enabled:
select count(*) from sys.change_tracking_tables where object_id=OBJECT_ID('TableName')
Detecting Changes
Change detection system works on a simple principle:
- Ask for changes to a specific table using table version number. If you are synchronising the table first table use 0 as version number. Note that if your table already has data and you’ve just enabled change tracking it won’t return any changes, therefore as a workaround you can treat all rows in that table as INSERT command.
- Read change table and parse it extracting all the relevant information.
- Depending on the change type you might need to query the database for full row data. In case of row deletes only ID is required.
- Remember version for the next sync session which is the maximum of all versions returned in step 3.
I’ll illustrate this with a few examples. Let’s create a simple table with integer as primary key and identity:
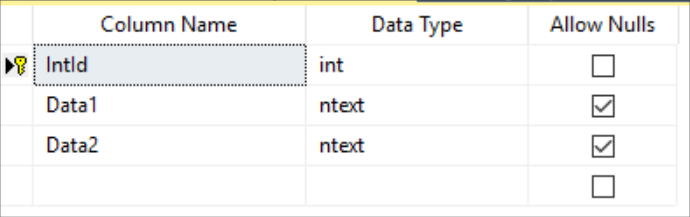
CREATE TABLE [dbo].[SimpleIntId](
[IntId] [int] IDENTITY(1,1) NOT NULL,
[Data1] [ntext] NULL,
[Data2] [ntext] NULL,
CONSTRAINT [PK_SimpleIntId] PRIMARY KEY CLUSTERED
(
[IntId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Use scripts from above to enable database and table change tracking. Now let’s insert a few rows into this table:
insert into SimpleIntId(Data1) values ('test data 1')
insert into SimpleIntId(Data1) values ('test data 2')
insert into SimpleIntId(Data1) values ('test data 3')
insert into SimpleIntId(Data1) values ('test data 4')
Now in order to query table for changes execute this command:
select * from CHANGETABLE(CHANGES [SimpleIntId], 3) as CT
Which will display the following result:

The query has two parameters:
- Table Name – in this case SimpleIntId is a table to watch.
- Version – is the last version you have synchronised. For a new sync session the number should be set to 0 to get all the changes. Next time you are fetching changes from the table you must use the biggest version number in
SYS_CHANGE_VERSIONcolumn, therefore if I need to track further changes to the table I need to pass number 7.
Unfortunately or fortunately this is all you get from the sync query. Important columns are:
SYS_CHANGE_VERSION. Indicates the version of the table when the change has occurred. You need this field value to ask for the next batch of changes.SYS_CHANGE_OPERATION. Is the actual operation performed on a row. The possible values are I, U and D indicating Insert, Update and Delete respectively.- The last colum(s). Are always named same as the tracking table keys. In our case we only have one key column (autoincrementing integer). The values are the values of the row key that was affected by the operation. Note that you need to query the table additionally to get the full row data you are interested in, change tracking does not include the actual data changed.
To contact me, send an email anytime or leave a comment below.