
Improving Parquet.Net Thrift Performance
Parquet.Net is a high-performance library for reading and writing Parquet files in .NET. It has achieved such a level of efficiency that it surpasses the native C++ implementation in speed. It has also reached a point where the bottleneck is no longer the data processing, but the metadata parsing, which is done using Apache Thrift.
This is a result of the recent efforts to optimize the performance of Parquet.Net, which have made it more apparent that Apache Thrift is the main source of overhead. Therefore, improving the performance of Apache Thrift or finding an alternative solution would be the next step to further enhance Parquet.Net.
Recent GitHub Issue “Very slow performance reading wide parquet file using V4” makes even users notice this, and is kind of embarrassing.
Therefore, I have decided to take action and work on optimizing the code to improve the speed and efficiency of this operation.
How Thrift is Utilised
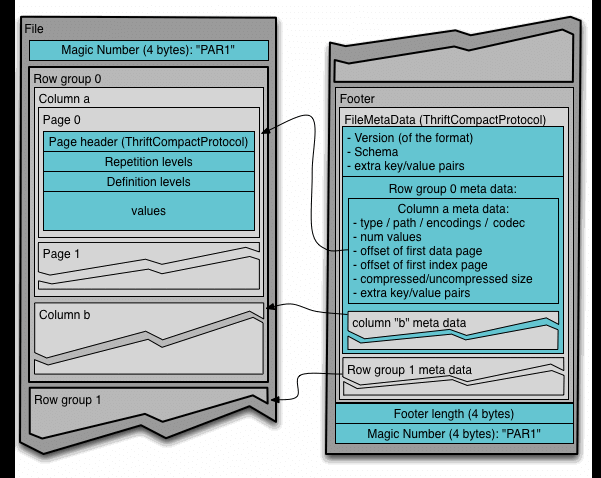
Parquet is a binary format that uses various algorithms to store data efficiently. One of the components of a parquet file is the Apache Thrift metadata, which provides essential information about the file structure and content. The metadata includes the schema of the data, the number of columns and row groups, the sizes of each row group and column chunk, and the physical locations of the data blocks within the file. The Apache Thrift metadata helps to locate and read the parquet data in a fast and flexible way.
It contains an info similar to this:
Thrift itself is cross-language and cross-platform. The data structures themselves are described in Thrift’s own Interface Definition Language (IDL), which for Parquet format is located here. The point of IDL is to generate language specific description of data structures for any language you want.
To do that, you would use something called a thrift compiler, which takes a .thrift file, and transforms it to a specific programming language. Here is a tutorial for C# but there are other languages supported out of the box too.
Unfortunately, code generated to C# is frankly suboptimal.
Issues in Standard Compiler
A lot of async calls
For instance, look at a really simple class definition with two fields:
public class DecimalType {
public int Scale { get; set; }
public int Precision { get; set; }
}
Now it’s corresponding autogenerated Write definition:
public async global::System.Threading.Tasks.Task WriteAsync(TProtocol oprot, CancellationToken cancellationToken)
{
oprot.IncrementRecursionDepth();
try
{
var tmp34 = new TStruct("DecimalType");
await oprot.WriteStructBeginAsync(tmp34, cancellationToken);
var tmp35 = new TField();
tmp35.Name = "scale";
tmp35.Type = TType.I32;
tmp35.ID = 1;
await oprot.WriteFieldBeginAsync(tmp35, cancellationToken);
await oprot.WriteI32Async(Scale, cancellationToken);
await oprot.WriteFieldEndAsync(cancellationToken);
tmp35.Name = "precision";
tmp35.Type = TType.I32;
tmp35.ID = 2;
await oprot.WriteFieldBeginAsync(tmp35, cancellationToken);
await oprot.WriteI32Async(Precision, cancellationToken);
await oprot.WriteFieldEndAsync(cancellationToken);
await oprot.WriteFieldStopAsync(cancellationToken);
await oprot.WriteStructEndAsync(cancellationToken);
}
finally
{
oprot.DecrementRecursionDepth();
}
}
This is how it’s designed for serialization using .NET. I appreciate author’s effort, but I have some concerns about the performance and readability of this code.
First of all, its’s using a lot of asynchronous calls to serialize two primitive fields. This seems unnecessary and inefficient, as each async call adds overhead and complexity to the code.
There are 5 asynchronous calls to serialize two primitive fields.
A lot of methods, for instance WriteFieldBeginAsync expands in more async calls. This one has 3, so you end up in 9 already. You get the idea. If you want to serialise more or less realistic data structure, that ends up in tens of thousands async calls and .NET just does context switching instead of doing the actual work.
Foreign Naming
One of the issues I encountered when generating code using the standard thrift compiler was the naming convention. The generated names did not follow the C# style and looked foreign. For example, public global::Parquet.Thrift.Encoding Definition_level_encoding { get; set; } does not match the C# naming guidelines. Definition_level_encoding should be DefinitionLevelEncoding in C#.
Fortunately, there is a simple solution if you are using C# to write a code generator. You can use the Humanizer library, which has a Pascalize method that converts any string to PascalCase automatically for you i.e.
using Humanizer;
string prettyName = "Definition_level_encoding".Pascalize(); // DefinitionLevelEncoding
Awkward Nullability
There’s one usability issue which was bothering me the most - optional or nullable fields. When your class has an optional enum member it can be null, but standard compiler generates it like so:
public global::Parquet.Thrift.ConvertedType Converted_type
{
get
{
return _converted_type;
}
set
{
__isset.converted_type = true;
this._converted_type = value;
}
}
where ConvertedType is an enum. In C# enums are value types and cannot be null, and there comes another weirdness - if enum is optional, you need to be aware of it when writing code, there is nothing in the class definition itself that tells you it can be null.
See that weird __isset.converted_type = true; in the setter? This basically sets a flag during deserialization that this member was set.
Now, in your code, if you need to check if enum is null, you will write awkward expressions like this:
if(tse.__isset.converted_type && tse.Converted_type == ConvertedType.UTF8)
// do something...
ConvertedTyp definition looks like the following:
public enum ConvertedType
{
/// <summary>
/// a BYTE_ARRAY actually contains UTF8 encoded chars
/// </summary>
UTF8 = 0,
/// <summary>
/// a map is converted as an optional field containing a repeated key/value pair
/// </summary>
MAP = 1,
// ...
}
Meaning if you don’t check that weird __isset member (which also has foreign naming scheme) you risk into assuming that the value is set to UTF8, but it’s not. It was a source of numerous bugs on my side, when I assumed I’m using valid C#.
How I fixed it
I was frustrated with the limitations and bugs of the existing thrift compiler, so I took on the challenge of creating a new one from scratch. My goal was to implement only the features that Parquet needs, which are a small subset of the full Thrift specification. This way, I could focus on optimizing the performance and reliability of the compiler, without worrying about compatibility with other Thrift applications.
Regular Expressions
My initial approach to the problem was to rely on regular expressions to parse the input.
This method seemed to work fine at first, but soon I encountered some difficulties when dealing with multiline comments and structs in the same regex. This made the parsing very complex and error-prone. As a result, I decided to discard this idea after two days of trial and error.
Regex is like a Swiss army knife: it has many tools, but none of them are very good. It can match patterns, but it can’t understand meaning. It can find words, but it can’t handle context. It can manipulate strings, but it can’t create logic. Regex is a powerful tool, but it’s not a smart one.
Back to Thrift Compiler
I was struggling with parsing IDL files for a long time. I wanted to generate C# code from them, but the syntax was too complex and ambiguous for me. Because I wanted everything from IDL parsed out perfectly - properties, types, structs, lists, and even comments.
I was about to give up, when a new idea struck me. What if I didn’t have to deal with IDL at all? What if I could convert it to another format that was easier to parse and manipulate? Maybe something like XML or JSON? That way, I could use existing parsers and serializers to handle the data structures and interfaces defined in IDL. I decided to give it a try and see if it would work.
If you run thrift compiler cli with -help switch it lists supported target formats for generation.
./thrift -help
gv (Graphviz):
exceptions: Whether to draw arrows from functions to exception.
...
html (HTML):
standalone: Self-contained mode, includes all CSS in the HTML files.
Generates no style.css file, but HTML files will be larger.
noescape: Do not escape html in doc text.
...
json (JSON):
merge: Generate output with included files merged
...
xml (XML):
merge: Generate output with included files merged
no_default_ns: Omit default xmlns and add idl: prefix to all elements
no_namespaces: Do not add namespace definitions to the XML model
...
xsd (XSD):
gv and html are although interesting, are I think mostly applicable to documentation files. gv is a language for defining graphs and diagrams using a simple syntax. It can be used with Graphviz, a software for visualizing graphs. html is a HTML. That means it can only make things look pretty, not do anything useful. Like a Kardashian.
JSON
But… if we look further, there isjson! Which seems li a perfect match! Parsing JSON is easy and anyone can do it. So I’ve ran the export and got parquet.json. To be honest, I thought that would be it, and IDL work is done. Unfortunately, for some reason JSON output does not include enough information to generate complex properties (structs) and lists. So I almost gave up again.
XML
I was looking for a way to extract more metadata from the API response, and I noticed that one of the available formats was XML. I decided to give it a try and compare it with the JSON output that I was using before. To my surprise, the XML format had all the information I needed, and it was easy to parse with a library. I felt lucky that I found a solution without much effort.
Working with XML is not as easy as JSON. However, in .NET, there is a convenient class called XElement that simplifies the creation and parsing of XML documents. With XElement, I can easily read the output of the IDL compiler and access the elements and attributes of the XML tree in code.
It helps to pass some options to thrift compiler to make xml a bit cleaner as well:
./thrift --gen xml:no_namespaces,no_default_ns
For all of this prototyping, I’ve used LinqPad and honestly enjoyed it more than ever.
How is it Looking Now
I’d say it’s looking great. Enums are enums and have correct XML documentations:
/// <summary>
/// DEPRECATED: Common types used by frameworks(e.g. hive, pig) using parquet. ConvertedType is superseded by LogicalType. This enum should not be extended. See LogicalTypes.md for conversion between ConvertedType and LogicalType.
/// </summary>
public enum ConvertedType {
/// <summary>
/// A BYTE_ARRAY actually contains UTF8 encoded chars.
/// </summary>
UTF8 = 0,
/// <summary>
/// A map is converted as an optional field containing a repeated key/value pair.
/// </summary>
MAP = 1,
// ...
}
XML documentation is also properly XML encoded, which doesn’t freak out C# compiler anymore.
I’m utilising C# nullable annotations to understand which optional fields were set:
/// <summary>
/// Statistics per row group and per page All fields are optional.
/// </summary>
public class Statistics {
/// <summary>
/// DEPRECATED: min and max value of the column. Use min_value and max_value. Values are encoded using PLAIN encoding, except that variable-length byte arrays do not include a length prefix. These fields encode min and max values determined by signed comparison only. New files should use the correct order for a column's logical type and store the values in the min_value and max_value fields. To support older readers, these may be set when the column order is signed.
/// </summary>
public byte[]? Max { get; set; }
public byte[]? Min { get; set; }
/// <summary>
/// Count of null value in the column.
/// </summary>
public long? NullCount { get; set; }
// ...
}
Write method is really compact and async-free:
internal void Write(ThriftCompactProtocolWriter proto) {
proto.StructBegin();
// 1: Scale, i32
proto.WriteI32Field(1, Scale);
// 2: Precision, i32
proto.WriteI32Field(2, Precision);
proto.StructEnd();
}
Comments can be removed, but I’m leaving them for debugging purposes for now.
Same for Read method:
internal static DecimalType Read(ThriftCompactProtocolReader proto) {
var r = new DecimalType();
proto.StructBegin();
while(proto.ReadNextField(out short fieldId, out CompactType compactType)) {
switch(fieldId) {
case 1: // Scale, i32
r.Scale = proto.ReadI32();
break;
case 2: // Precision, i32
r.Precision = proto.ReadI32();
break;
default:
proto.SkipField(compactType);
break;
}
}
proto.StructEnd();
return r;
}
Numbers
Straight rewrite with no performance optimisations and just optimising for minimalism and style gave 10x performance increase:
| Method | Mean | Ratio | Gen0 | Gen1 | Gen2 | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|
| Read_Standard | 47.326 ms | 1.00 | 416.6667 | 250.0000 | - | 2.71 MB | 1.00 |
| Read_Mine | 4.580 ms | 0.10 | 773.4375 | 757.8125 | 7.8125 | 4.52 MB | 1.66 |
After analysing code, a lot of time was spent in LINQ for deserialising lists, in this piece of code:
r.PathInSchema = Enumerable.Range(0, proto.ReadListHeader(out _)).Select(i => proto.ReadString()).ToList();
Therefore I’ve replaced it with a more verbose version:
elementCount = proto.ReadListHeader(out _);
r.PathInSchema = new List<string>(elementCount);
for(int i = 0; i < elementCount; i++) { r.PathInSchema.Add(proto.ReadString()); }
which gave another performance boost, and now it’s 12.5x faster:
| Method | Mean | Ratio | Gen0 | Gen1 | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| Read_Standard | 45.990 ms | 1.00 | 454.5455 | 363.6364 | 2.71 MB | 1.00 |
| Read_My | 3.505 ms | 0.08 | 605.4688 | 476.5625 | 3.34 MB | 1.23 |
Now the slowest method is reading byte[]:
public byte[] ReadBinary() {
// read length
int length = (int)ReadVarInt32();
if(length == 0) {
return Array.Empty<byte>();
}
// read data
return _inputStream.ReadBytesExactly(length); // <-- here
}
which is my own extension method:
public static byte[] ReadBytesExactly(this Stream s, int count) {
byte[] tmp = new byte[count];
int read = 0;
while(read < count) {
int r = s.Read(tmp, read, count - read); // <-- here
if(r == 0)
break;
else
read += r;
}
if(read < count)
throw new IOException($"only {read} out of {count} bytes are available");
return tmp;
}
Unfortunately there’s not much I can do quickly to optimise Stream.Read CLR method at the moment, so I’m leaving it for now.
Summary
This work has achieved the following:
- Thrift performance is 12.5 times faster, which was the original goal.
- Thrift generated classes now look and behave native to C#.
- Optional fields are utilising
Nullable<T>pattern. - Optional classes are using nullable annotations.
- Naming conventions are native to C#.
- XML documentation looks correct.
- Optional fields are utilising
Links
To contact me, send an email anytime or leave a comment below.